Distributed systems are a special class of systems that are composed of multiple autonomous computers that communicate and coordinate their actions by passing messages to one another.
- Heterogeneity;
- Openness;
- Security;
- Scalability;
- Fault Tolerance;
- Concurrency;
- Transparency;
- Quality of Service (QoS);
Heterogeneity refers to the ability for the system to operate on a variety of different hardware and software components. This is achieved through the implementation of middle-ware in the software layer.
- Different network topologies;
- Hardware;
- Operating systems;
- Programming languages;
- Databases with different paradigms;
- Different environments.
Through numerous norms and standards, the interoperability between different systems has been improved: TCP/IP, HTTP, XML, SOAP, etc.
The openness of a distributed system is defined as the difficulty involved to extend or improve an existing system. This characteristic allows us to reuse a distributed system for multiple functions or to process varying sets of data.
- With the heterogeneity of the system, its specification and documentation must be open to the public;
- RFCs (Request for Comments) are a good example of open specifications;
- Confidentiality: the ability to prevent unauthorized access to information;
- Integrity: the ability to prevent unauthorized modification of information;
- Authentication: the ability to verify the identity of a user or process;
- Authorization: the ability to prevent a user or process from accessing resources that it is not authorized to access;
- Availability: the ability to prevent denial of service attacks.
Challenges:
- Denial of service attacks;
- Identity theft.
Scalability is the ability of a system to cope with increased load by adapting its resources. This characteristic is achieved through the use of load balancing and replication.
- Load balancing: the distribution of the load among multiple servers;
- Replication: the duplication of data and services in multiple servers.
The elasticity of a system is the ability to adapt its resources to the current load automatically. The increase/decrease of resources is dynamic, based on some conditions:
- Increase of CPU usage;
- At a certain time of the day, or day of the week;
- Increase of the number of users.
The key difference between scalability and elasticity is that scalability is manual and elasticity is automatic.
Fault tolerance is the ability of a system to continue operating in the presence of faults. The faults in a distributed system are partial.
Techniques to achieve fault tolerance:
- Replication: the duplication of data and services in multiple servers (e.g. server clusters, RAID (Redundant Array of Independent Disks));
- Message retransmission: the retransmission of a message that has not been received by the destination;
- Rollback recovery: the recovery of a transaction that has failed.
A Byzantine fault is a fault that is not partial. It is a fault that is malicious and arbitrary. It is a fault that is unpredictable and uncontrollable, that describes the worst case scenario.
A system only has to tolerate Byzantine faults if it stays working even if some parts of the system do not (e.g. a bank system, aerospace systems).
Concurrency is the ability of a system to execute multiple processes at the same time. This characteristic is achieved through the use of synchronization and asynchronization.
The main challenges of concurrency are:
- Transaction management;
- Concurrent access to shared resources;
- Consistency of data.
Transparency is the ability of a system to hide its internal complexity from the user. This characteristic is achieved through the use of abstraction.
- Access transparency: access to local and remote resources uses the same interface;
- Location transparency: the location of a resource is transparent to the user;
- Migration transparency: allows the migration of a resource from one node to another, without affecting the access to the resource;
- Concurrency transparency: multiple concurrent accesses should not affect the consistency of the data;
- Replication transparency: the user should not be aware of the replication of data and services;
- Failure transparency: the user should not be aware of the failure of a resource, allowing it to continue operating. This ia a very complex, or even impossible, characteristic to achieve;
- Performance transparency: allows the system to adapt its resources to the current load;
- Scalability transparency: allows the system scalability to be transparent to the user.
Note: there are trade-offs between high levels of transparency and performance.
Quality of Service (QoS) is the ability of a system to provide a certain level of service to the user.
The main characteristics that affect QoS are:
- Reliability: the ability of a system to provide a service without failures;
- Security;
- Availability;
- Performance;
- Adaptability.
Some important QoS metrics:
- Response time;
- Workloads;
- Possibility to monitorize and define restrictions that ensure the SLA (Service Level Agreement);
The CAP Theorem states that it is impossible for a distributed system to simultaneously provide more than two out of the following three guarantees: Consistency, Availability and Partition Tolerance.
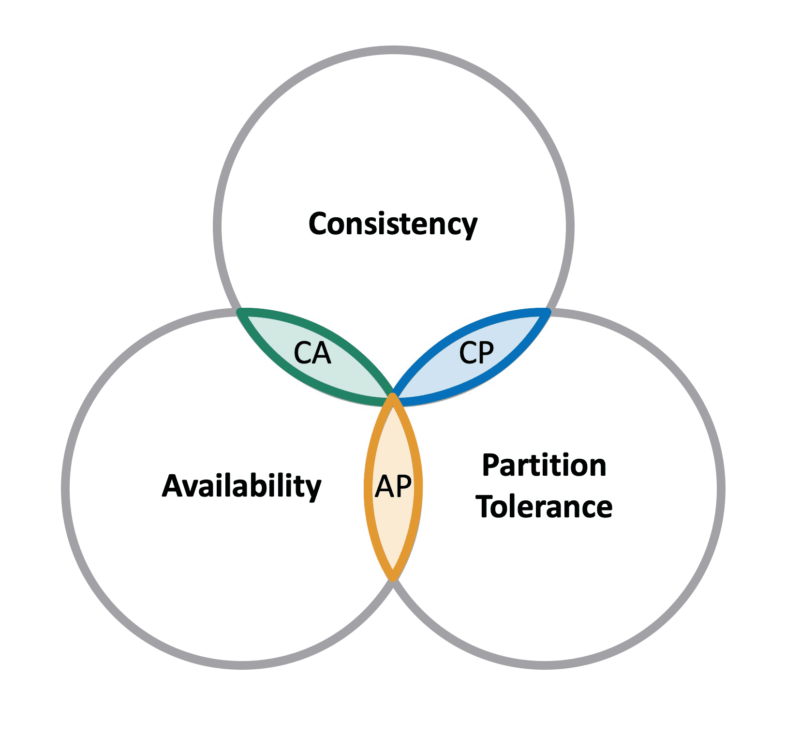
- Consistency: all nodes see the same data at the same time;
- Availability: the system is always available to process requests, even in the presence of failures, or connectivity problems;
Uptime / (Uptime + Downtime) >= 99.999%;- Five 9s (99.999%) is the standard for availability;
- Partition Tolerance: the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
BASE: Basically Available, Soft state, Eventually consistent.
- The network is reliable;
- The latency is zero;
- The bandwidth is infinite;
- The network is secure;
- Topology doesn't change;
- There is one administrator;
- Transport cost is zero;
- The network is homogeneous.
Latency is the time it takes for a message to travel from one node to another.
Bandwidth is the amount of data that can be sent in a given time.