
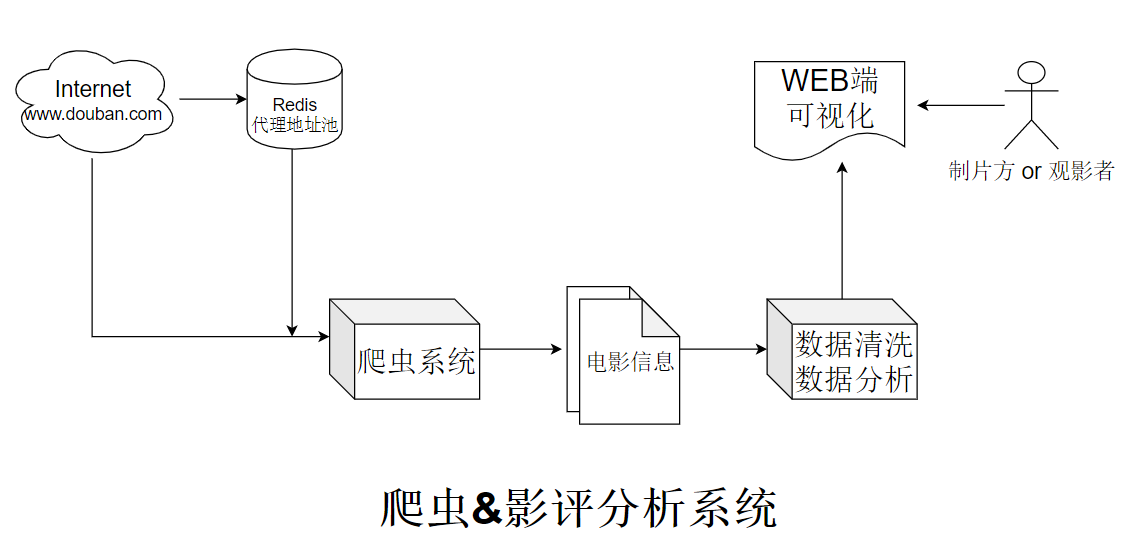
这个项目是利用Python爬虫技术豆瓣top500的影视数据并使用pandas、jieba等数据分析工具对其进行清洗分析;进一步使用pyecharts等可视化工具完成影视数据可视化,如制作各种图表,WEB前端展示;最后使用snowNLP等中文情感分析工具对影评进行情感分析获得人们对影片的情感分数,以呈现有价值的数据。通过对现阶段影视行业相关数据的采集与分析,本文能够为观影者和投资方提供更符合个性需求的信息推荐。
该项目在Windows系统中使用Python 3.7.3版本进行开发,其中调用第三方库如Requests、Flask、Pyredis等库完成代理池的开发和维护;结合Requests、BeautifulSoup等第三方库完成电影信息的爬虫任务;利用Pyecharts、jieba、WordCloud等第三方库绘制各种图表;最后使用snowNLP、pandas、numpy等第三方库完成影评的情感分析。
| module |
directory |
| 代理池模块 |
proxypool |
| 爬虫模块 |
moviespider |
| 数据分析模块 |
analyse |
| 前端模块 |
proxypool/processors/server.py |
- 安装 python 3.6+
- 安装依赖
pip3 install -r requirements.txt
- 运行代理池和WEB前端
python3 run.py
- 运行影片爬虫模块
python3 moviespider/main.py
- 运行数据分析模块
- top500影片信息分析
python3 analyse/movie_analyse.py
- 影片分析
python3 analyse/comment_analyse.py
| 列名 |
数据类型 |
可否为空 |
说明 |
| 名称 |
str |
否 |
电影名称 |
| 年份 |
datatime |
否 |
电影发行年份 |
| 导演 |
str |
否 |
多个导演则逗号分割 |
| 演员 |
str |
否 |
多个演员则逗号分割 |
| 类型 |
str |
否 |
多个类型则逗号分隔 |
| 国别 |
str |
否 |
多个国别则逗号分隔 |
| 语言 |
str |
否 |
多个语言则逗号分割 |
| 评分 |
int |
否 |
/ |
| 评分人数 |
int |
否 |
/ |
| 五星占比 |
str |
否 |
五星评分的人数占比 |
| 四星占比 |
str |
否 |
四星评分的人数占比 |
| 三星占比 |
str |
否 |
三星评分的人数占比 |
| 二星占比 |
str |
否 |
二星评分的人数占比 |
| 一星占比 |
str |
否 |
一星评分的人数占比 |
| 短评数 |
int |
否 |
/ |
| 简介 |
str |
否 |
/ |
| 列名 |
数据类型 |
可否为空 |
说明 |
| 用户 |
str |
否 |
发表评论的用户名 |
| 是否看过 |
str |
否 |
评论的用户是否看过该影片 |
| 评分 |
str |
否 |
力荐/推荐/还行/较差/很差 |
| 评论时间 |
datatime |
否 |
/ |
| 有用数 |
int |
否 |
该评论获得点赞的次数 |
| 评论 |
str |
否 |
评论内容 |

