- Person or organization developing model: Patirck Hall,
[email protected]& Shuning Ma,[email protected] - Model date: June, 2022
- Model version: 1.0
- License: Apache License 2.0
- Model implementation code: DNSC6290
Final selected model is Monotonic XGBoost, and the other models are here for comparison.
- Training basic interpretable models
- Post-hoc explanations
- Bias testing
- Red-teaming
- Model debugging
- Primary intended uses: This model is an example probability of XGBoost model, with an example use case for determining whether (1) or not (0) the annual percentage rate (APR) charged for a mortgage is 150 basis points (1.5%) or more above a survey-based estimate of similar mortgages.
- Primary intended users: Students in GWU DNSC 6290 course.
- Out-of-scope use cases: Any use beyond an educational example is out-of-scope.
- Data dictionary:
| Name | Modeling Role | Measurement Level | Description |
|---|---|---|---|
| row_id | ID | int | unique row indentifier |
| black | demographic information | binary | 1 = black; 0 = non-black |
| asian | demographic information | binary | 1 = asian; 0 = non-asian |
| white | demographic information | binary | 1 = white; 0 = non-white |
| amind | demographic information | binary | 1 = amind; 0 = non-amind |
| hipac | demographic information | binary | 1 = hipac; 0 = non-hipac |
| hispanic | demographic information | binary | 1 = hispanic; 0 = non-hispanic |
| non_hispanic | demographic information | binary | 1 = non_hispanic; 0 = hispanic |
| male | demographic information | binary | 1 = male; 0 = female |
| female | demographic information | binary | 1 = female; 0 = male |
| agegte62 | demographic information | binary | 1 = agegte62; 0 = agelt62 |
| agelt62 | demographic information | binary | 1 = agelt62; 0 = agegte62 |
| conforming | inputs | binary | 1 = the mortgage conforms to normal standards; 0 = the loan is different |
| debt_to_income_ratio_std | inputs | float | standardized debt-to-income ratio for mortgage applicants |
| debt_to_income_ratio_missing | inputs | binary | 1 = missing debt_to_income_ratio_std; 0 = non-missing debt_to_income_ratio_std |
| income_std | inputs | float | standardized income for mortgage applicants |
| loan_amount_std | inputs | float | standardized amount of the mortgage for applicants |
| intro_rate_period_std | inputs | float | standardized introductory rate period for mortgage applicants |
| loan_to_value_ratio_std | inputs | float | ratio of the mortgage size to the value of the property for mortgage applicants |
| no_intro_rate_period_std | inputs | binary | -4.09174686250922 = a mortgage does not include an introductory rate period; 0.244394395255126 = a mortgage includes an introductory rate period |
| property_value_std | inputs | float | value of the mortgaged property |
| term_360 | inputs | binary | 1 = the mortgage is a standard 360 month mortgage; 0 = the mortgage is a different type of mortgage |
| high_priced | target | binary | whether the annual percentage rate (APR) charged for a mortgage is (not) 150 basis points (1.5%) or more above a survey-based estimate of similar mortgages, 1 = is; 0 = not |
- Source of training data: Home Mortgage Disclosure Act (HMDA) data
- How training data was divided into training and validation data: 70% training, 30% validation
- Number of rows in training and validation data:
- Training rows: 112,253
- Validation rows: 48,085
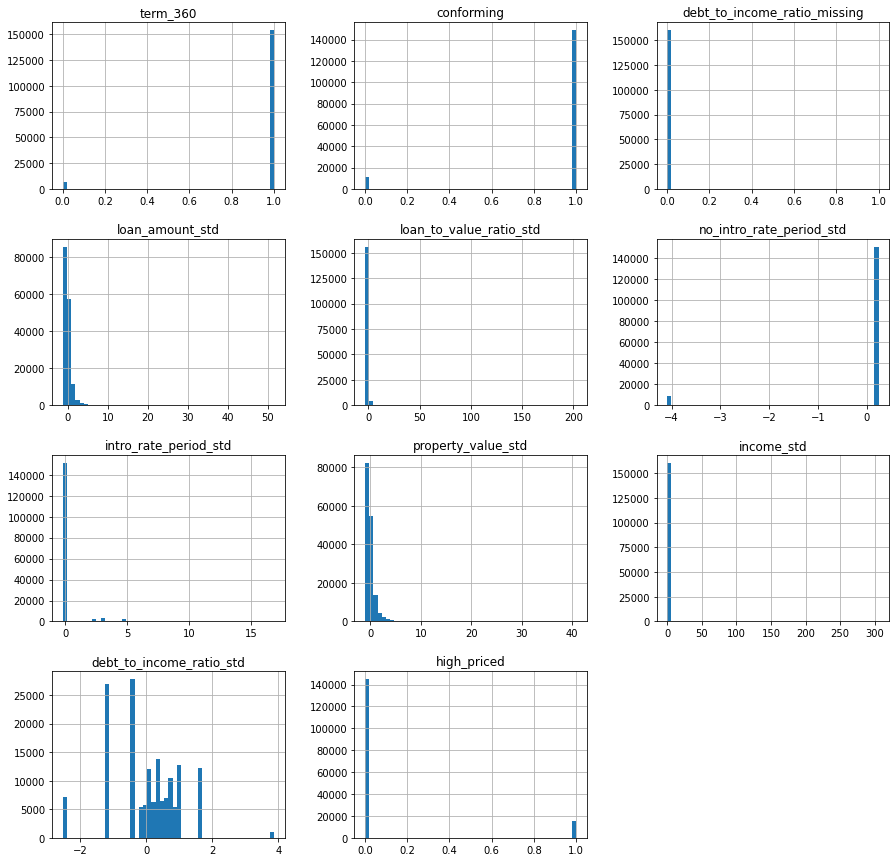
- Source of test data: Home Mortgage Disclosure Act (HMDA) data
- Number of rows in test data: 19,831
- State any differences in columns between training and test data: The test data does not contain the target column.
- Final selected model: Monotonic XGBoost
- Columns used as inputs in the final model: 'term_360', 'conforming', 'debt_to_income_ratio_missing', 'loan_amount_std', 'loan_to_value_ratio_std', 'no_intro_rate_period_std', 'intro_rate_period_std', 'property_value_std', 'income_std', 'debt_to_income_ratio_std'
- Column(s) used as target(s) in the final model: 'high_priced'
- Type of model: Monotonic XGBoost model
- Software used to implement the model:
h2o,interpret,jupyter,matplotlib,numpy,pandas,scikit-learn,seaborn,xgboost - Version of the modeling software:
- h2o==3.32.1.3
- interpret==0.2.4
- jupyter==1.0.0
- matplotlib==3.3.4
- numpy==1.19.5
- pandas==1.1.5
- scikit-learn==0.24.2
- seaborn==0.11.1
- xgboost==1.4.2
- Hyperparameters or other settings of your model:
- 'colsample_bytree': 0.3,
- 'colsample_bylevel': 0.3,
- 'eta': 0.05,
- 'max_depth': 3,
- 'reg_alpha': 0.0005,
- 'reg_lambda': 0.0005,
- 'subsample': 0.3,
- 'min_child_weight': 10,
- 'gamma': 0.2
- 'n_jobs': 4,
- 'random_state': 12345,
- 'mono_constraints': (1, 1, 1, -1, 0, -1, 0, 1, 0, 1)
-
Metrics used to evaluate your final model: AUC & AIR
-
State the final values of the metrics for all data: training, validation, and test data:
Partition AUC Training 0.7894 Validation 0.7907 Evaluation 0.8294 Compare v. Control AIR Asian people vs. White people 1.146 Black people vs. White people 0.805 Females vs. Males 0.949 -
Provide any plots related to your data or final model -- be sure to label the plots!:
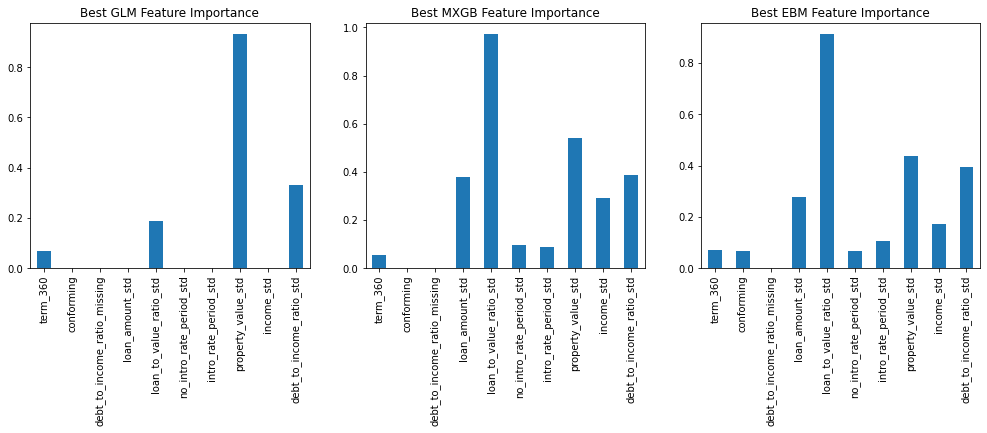
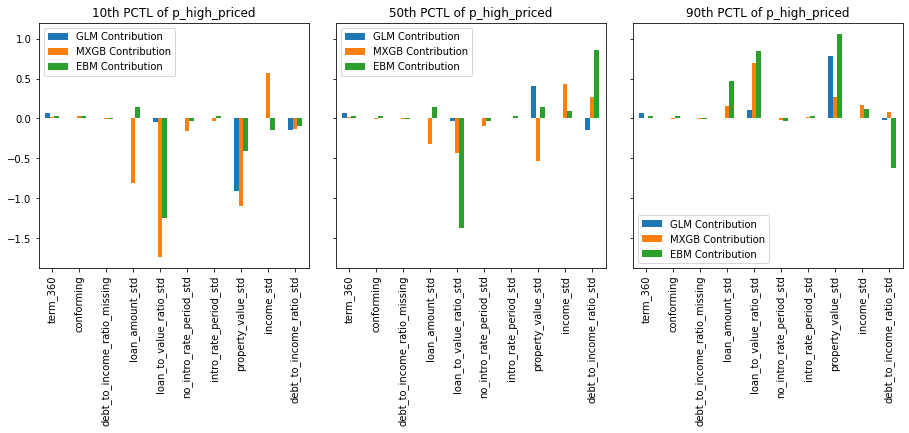
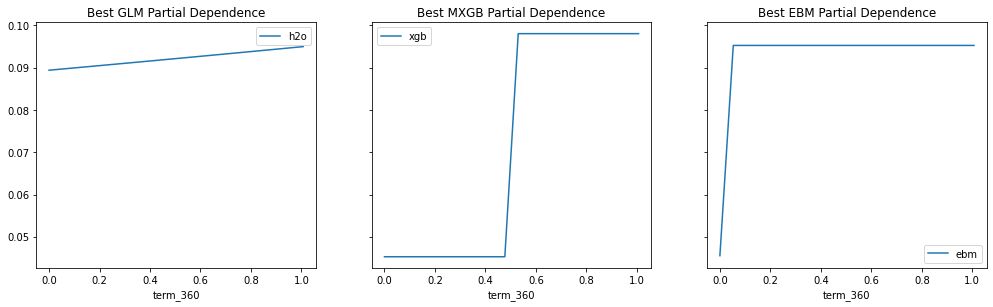

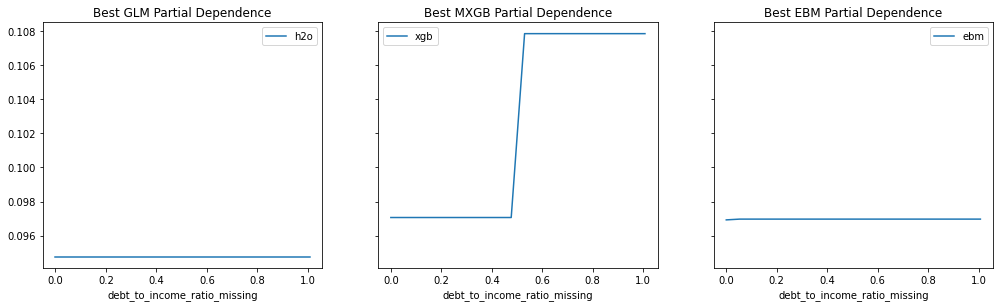
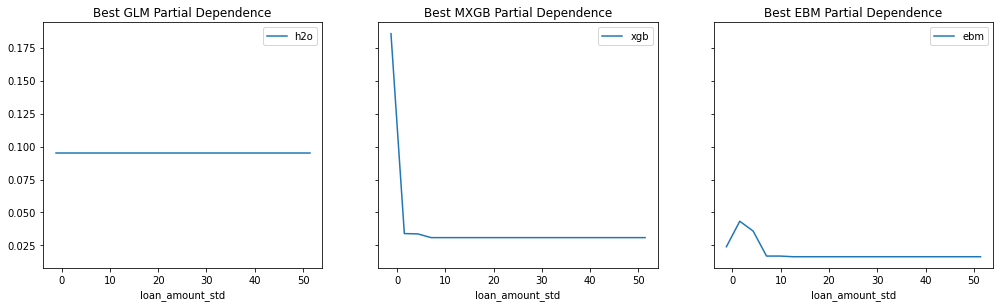
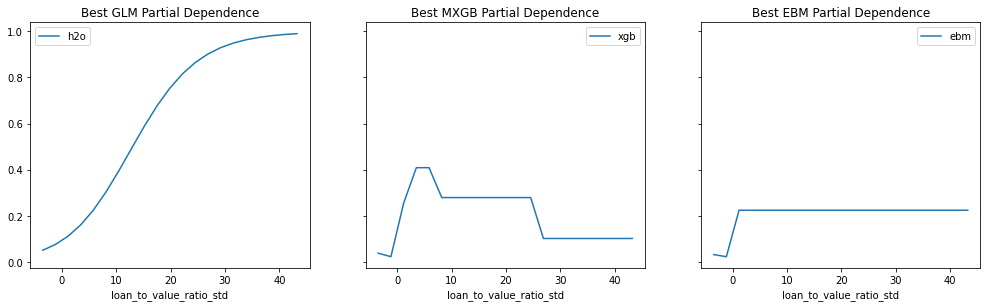
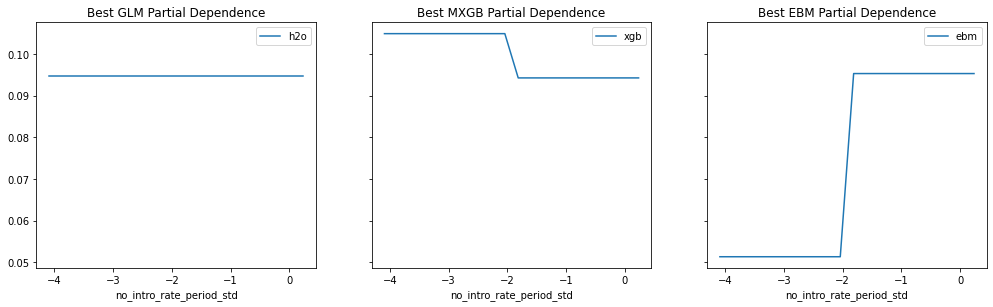
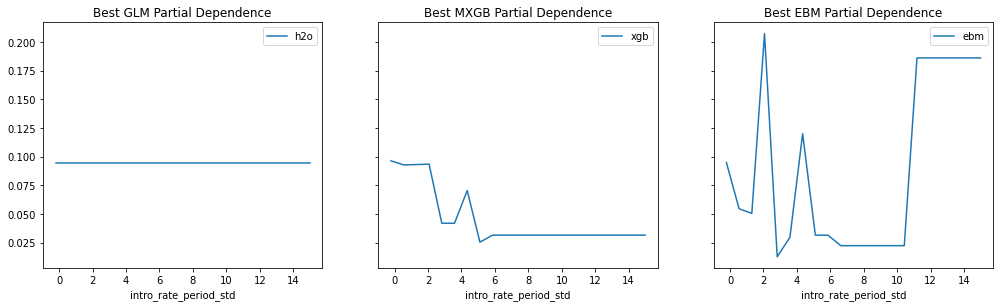
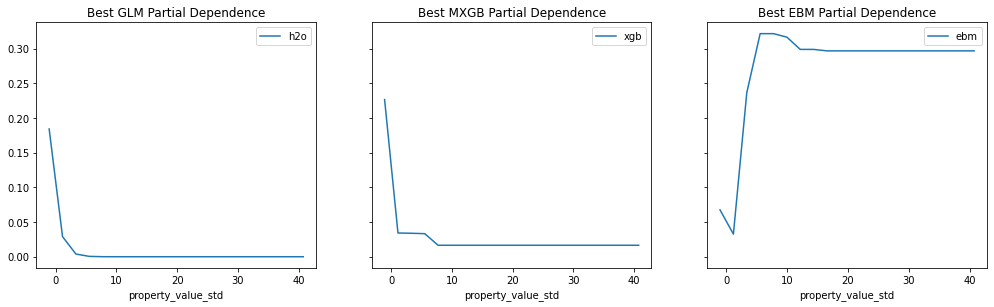

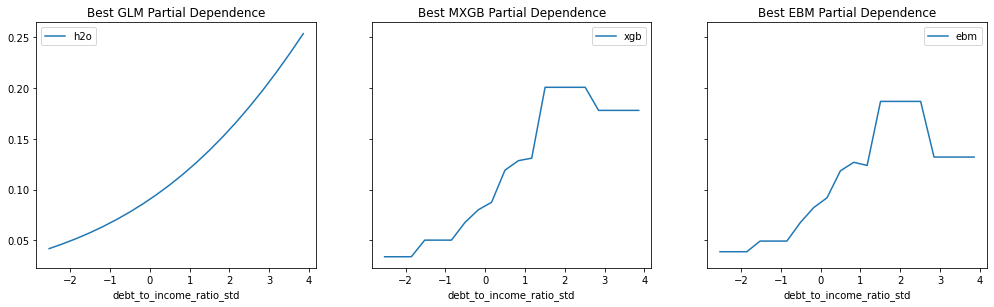
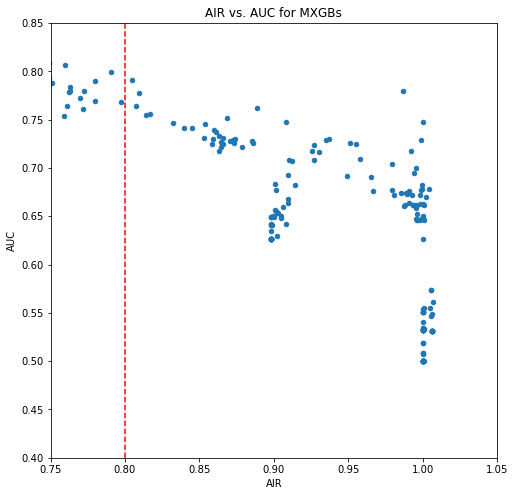
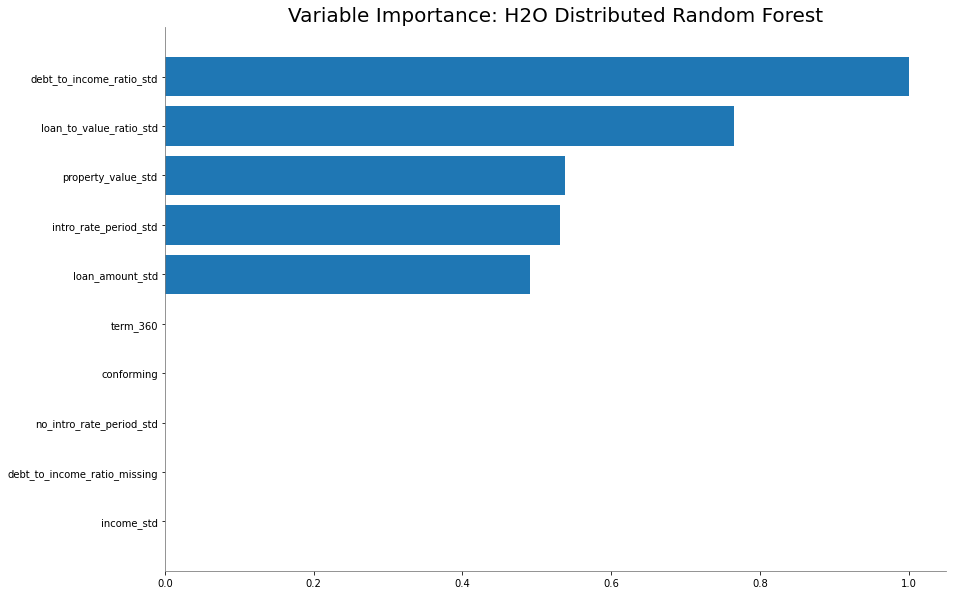
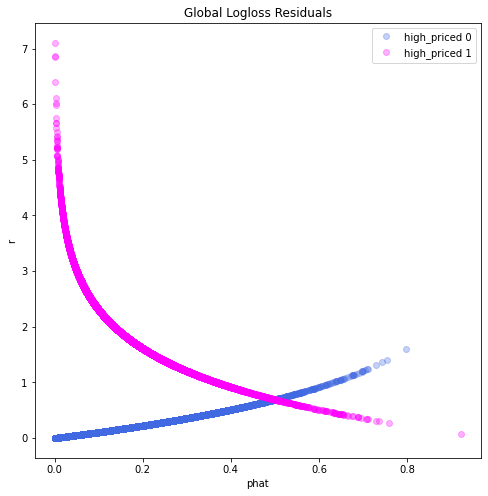
- Describe potential negative impacts of using your model
- Math or software problems: Due to compatibility issues between
h2oandxgboost, the stolen decision tree model generated had unusual big numbers, causing adversial examples full of missing values. - Real-world risks: who, what, when or how: The adverse impact ratio of Black-to-White, although > 0.8, is relatively low (0.805), which could lead to unfair difference in outcomes. When using this model to predict high-priced mortgages, for every 100,000 low-priced loans to white people, there are only 80,500 low-priced loans to Black people.
- Math or software problems: Due to compatibility issues between
- Describe potential uncertainties relating to the impacts of using your model
- Math or software problems: With different versions of software, some codes may need to be changed, especially for
xgboost. - Real-world risks: who, what, when or how: Hackers may steal the model to do model extraction attack. According to adversial examples results in Red-teaming, the hackers can get predictions they want by inputting missing values in multiple features.
- Math or software problems: With different versions of software, some codes may need to be changed, especially for
- Describe any unexpected or results: Although this model was tested and remediated for bias, there is much more to bias than models and data, and this model should be monitored for bias issues moving forward.